Power BI数据集横向扩展初识
本周闲时和同时闲聊了下技术的瓶颈,技术肯定是有瓶颈的,拿公司最常用的mysql举例,限制就不要太多,解决起来也有简单粗爆的方法,换商业收费数据库。那对于人而言,技术有没有瓶颈呢?也是有的,但瓶颈在于我学不会了,跟不上技术的发展了。所以,最终得出结论,技术的瓶颈在于我,毕竟技术发展实在太快,必须要一直与时俱进;那么问题也来了,为什么我不转相对来说发展比较慢的管理岗呢?
回归正题,我司目前最大的Power BI数据集已经在1G以上了,为了符合业务人员看Excel的习惯,前端还存在大量的复杂表格,高峰使用时期查询不要太卡,但是一味提sku成本未免太高,比如Power BI Embedded A4每月成本已近4万。A6更是高达15万,这是在喝公司的血啊。。。
好在本周微软发布了数据集横向扩展的公开预览版,Announcing automatic scaling for dataset scale-out public preview | Microsoft Power BI 博客 | Microsoft Power BI — 宣布数据集横向扩展公共预览版自动扩展 |微软 Power BI 博客 |微软Power BI总的来说就是有两个优点
- 提高性能,通过多个数据集副本,可以减少查询延迟和提高数据集吞吐量
- 减少刷新影响,通过将只读副本与读写副本分开,可以减少刷新操作对报告和仪表板的影响。刷新数据集时,Power BI 仅更新读写副本,而只读副本继续提供查询服务。
先决条件
- 必须使用Power BI REST API
- 开启横向扩展
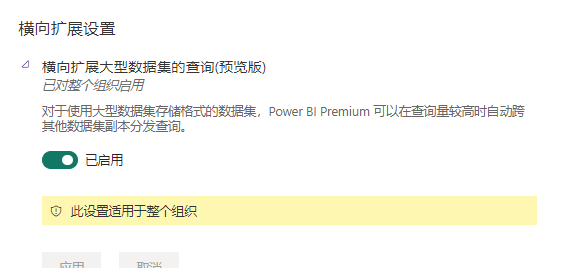
- 使用高级容量工作区
- Premium Per User (PPU)
- Power BI Premium P SKU
- 用于 Power BI Embedded 的 Power BI A SKU(目前在世纪互联版上测试开启失败,暂未找到原因)。
- Fabric F SKU
限制
目前数据集横向扩展还有很多限制,具体可参见Power BI 数据集横向扩展 – Power BI | Microsoft Learn
配置横向扩展
可参考官方的方法,配置 Power BI 数据集横向扩展 – Power BI | Microsoft Learn,不过官方使用的是Power Shell命令。。。还是转为相对熟悉的python吧
获取token
如果还没有创建应用的,需要登录Azure门户创建,这里不再展开,可参考先前文章
获取数据集横向扩展状态
关于数据集的id和工作区id可在Power BI门户中查看,使用的API详见官方文档Datasets – Trigger Query Scale Out Sync In Group – REST API (Power BI Power BI REST APIs) | Microsoft Learn — 数据集 – 触发查询横向扩展同步输入组 – REST API(Power BI Power BI REST API)| 数据集 – 触发查询横向扩展同步输入组 – REST API(Power BI Power BI REST API)微软学习,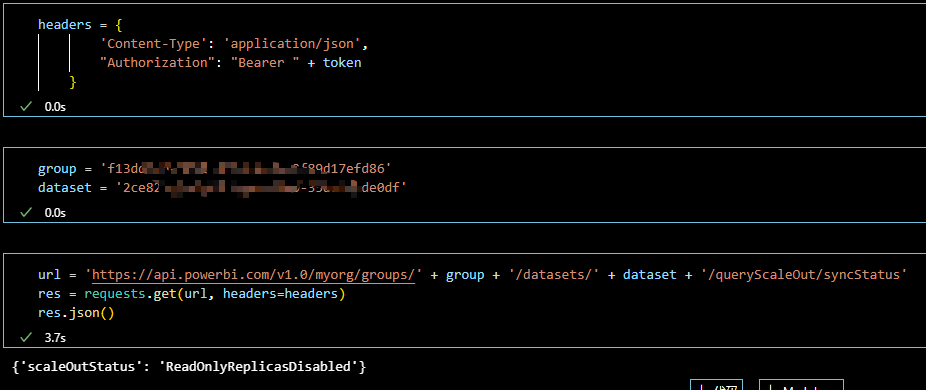
可以看到目前数据集是未启用状态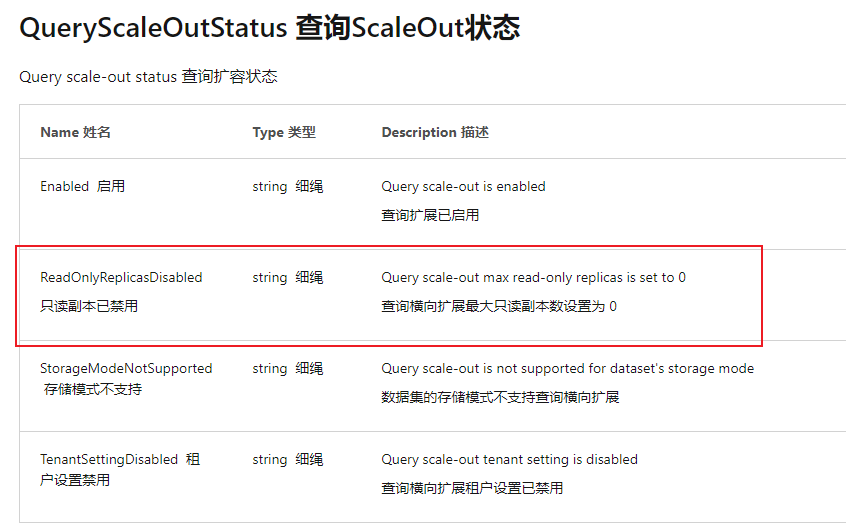
启用数据集横向扩展
若要启用数据集横向扩展,请将 maxReadOnlyReplicas 设置 -1,或任何其他非零值。 -1 的值允许 Power BI 创建 Power BI 容量支持的许多只读取副本。 还可以将副本计数明确设置为小于最大容量的一个值。 建议将 maxReadOnlyReplicas 设置为 -1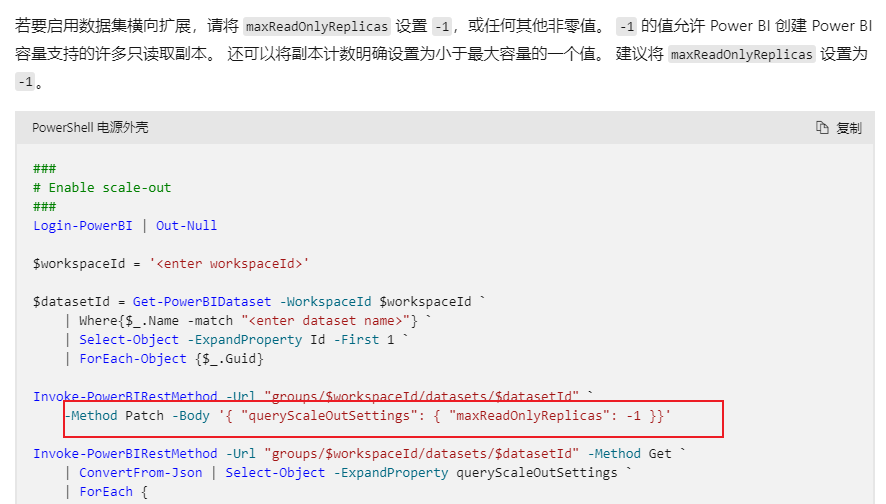
这里有点郁闷,代码明明报错了,但是再次查询,状态已经启用了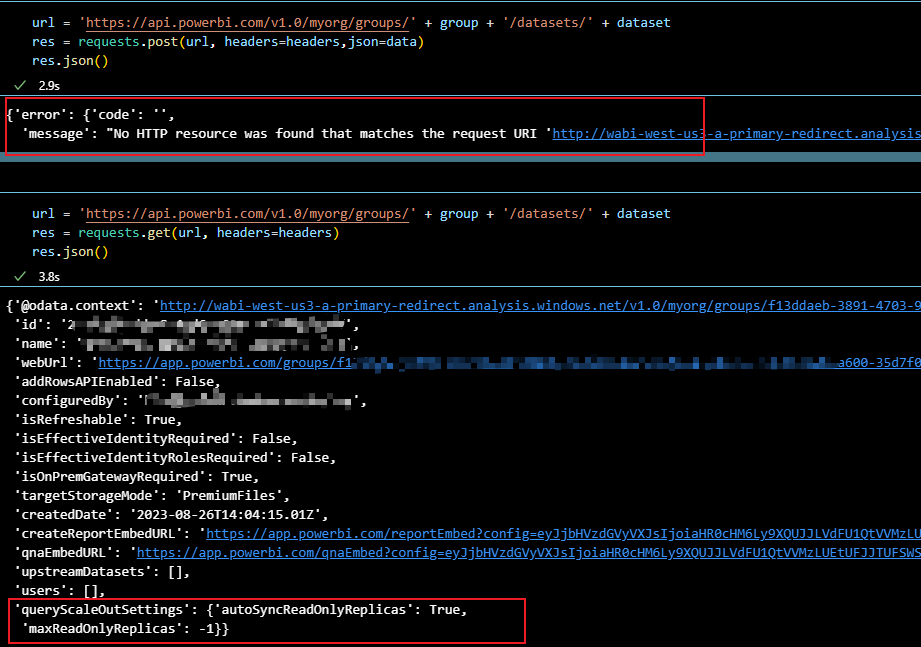
保险起见再次查询下状态,显示已经启用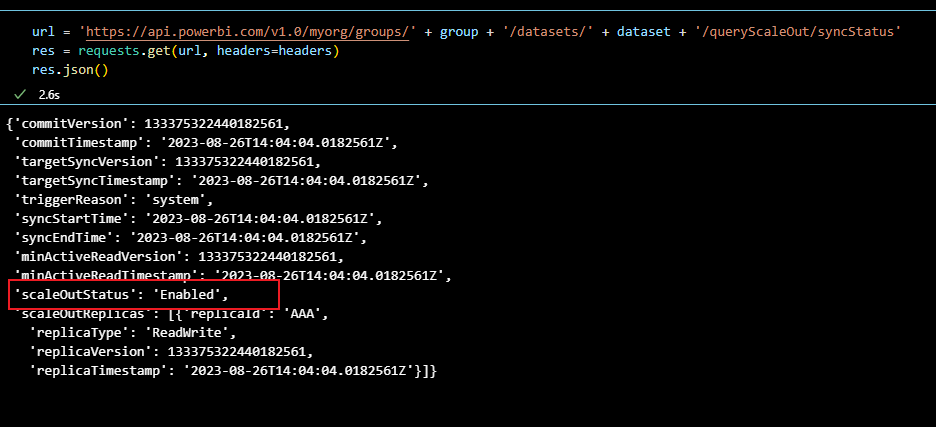
总结
不知道是不是测试用数据集比较小的原因,实际体验下来并没有感觉速度变快,不知道未来正式版会不会有所改善,另外,希望可以在门户中通用可视化界面来操作,而不是必须通过Power BI REST API,知道你微软啥都有接口值得夸奖,但还是界面操作更用户友好些。。。。